一��、面板數(shù)據(jù)回歸分析的Stata實現(xiàn)
?
? ?作為功能全面��、操作簡明的統(tǒng)計分析工具���,Stata在數(shù)據(jù)處理與模型估計方面具有顯著優(yōu)勢�。其系統(tǒng)整合了數(shù)據(jù)管理��、統(tǒng)計分析與圖形展示等功能���,尤其擅長處理面板數(shù)據(jù)�、時間序列數(shù)據(jù)及復雜調查數(shù)據(jù)。對于會計學領域的研究而言�����,面板數(shù)據(jù)因其能夠同時反映個體與時間維度的變化而得到廣泛使用���。因此,熟練掌握Stata中面板數(shù)據(jù)的回歸操作方法�����,具有重要的學術價值與實踐意義�。
? ?本文旨在介紹基于Stata進行面板數(shù)據(jù)回歸分析的主要步驟與相關命令。具體內(nèi)容涵蓋模型設定�����、估計方法選擇以及結果解釋等方面���,為相關研究提供技術參考���。
 ?
?
二、面板數(shù)據(jù)的基本概念
?
? ?面板數(shù)據(jù)���,亦稱縱列數(shù)據(jù)或追蹤數(shù)據(jù)���,是計量經(jīng)濟學與統(tǒng)計學研究中一種重要的數(shù)據(jù)結構�����。它是指在時間維度上對一組固定個體進行重復觀測所獲得的數(shù)據(jù)集合��,本質上是截面數(shù)據(jù)與時間序列數(shù)據(jù)的有機結合�����。
? ?具體而言�,面板數(shù)據(jù)包含兩個維度:截面維度(通常為不同的個體�����,如地區(qū)�、機構或家庭)與時間維度(連續(xù)的觀測時期)。例如��,在研究省級經(jīng)濟發(fā)展時�,若對31個省級行政區(qū)連續(xù)觀測38年(如1979年至2016年),便可得到一個包含1178個觀測值的平衡面板數(shù)據(jù)集�����。這種數(shù)據(jù)結構能夠同時反映個體間的差異與個體隨時間的變化趨勢,為控制不可觀測的個體異質性提供了可能���,因而在實證研究中具有顯著優(yōu)勢��。
?
三���、面板數(shù)據(jù)模型的優(yōu)勢?
?
? ?面板數(shù)據(jù)模型在計量經(jīng)濟分析中具有若干顯著優(yōu)勢�,主要體現(xiàn)在以下幾個方面:
?
? ?首先,該模型能夠有效控制不可觀測的個體異質性與時間效應��。在實證研究中����,常存在諸如地區(qū)文化、個體偏好或特定時期沖擊等難以量化或觀測的因素�。若忽略這些因素,可能導致遺漏變量偏誤����。面板數(shù)據(jù)模型通過引入個體固定效應或時間固定效應,能夠在估計過程中控制這些不隨時間變化或不在個體間變化的特征��,從而提升參數(shù)估計的一致性。
?
? ?其次��,面板數(shù)據(jù)結構包含更多信息與變異�����。由于同時結合了截面與時間兩個維度�����,其觀測值數(shù)量通常顯著增加���,這不僅提高了估計的自由度�����,也能減弱解釋變量間可能存在的多重共線性問題�,從而提升估計效率與統(tǒng)計推斷的可靠性��。
?
? ?最后����,面板數(shù)據(jù)模型特別適用于分析經(jīng)濟行為的動態(tài)調整過程。例如,個體的當期決策常受到過去行為的影響����,面板數(shù)據(jù)允許研究者將滯后因變量納入模型,從而更準確地刻畫和檢驗這種動態(tài)依賴關系��。
 ?
?
四�、面板模型的選擇:固定效應與隨機效應
?
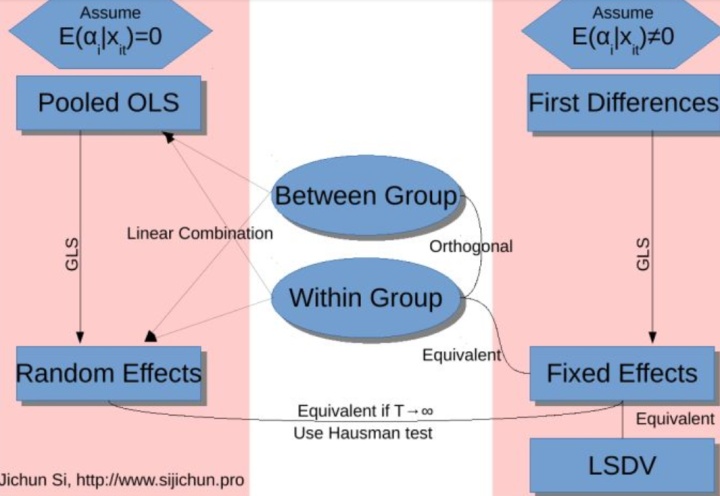
? ?在面板數(shù)據(jù)分析中,處理不可觀測的個體效應主要存在兩種方法�,由此衍生出兩種基本模型:固定效應模型與隨機效應模型。二者核心區(qū)別在于對個體效應性質的設定不同����。
?
? ?固定效應模型將個體差異視為待估參數(shù),表現(xiàn)為每個個體擁有獨特的截距項��。該模型允許個體效應與模型中的解釋變量存在任意相關性����,其估計目標在于分析樣本內(nèi)個體自身的動態(tài)變化����。相比之下,隨機效應模型則將個體差異視為來自某一總體的隨機變量���,并納入復合誤差項����。該模型假定個體效應與所有解釋變量均不相關,其估計目標在于對總體特征進行推斷�����。
?
? ?關于模型選擇����,一種觀點依據(jù)研究樣本與母體的關系。若樣本近乎構成研究對象的全部(如對中國全部省級行政區(qū)的研究)�����,個體效應可視為固定參數(shù)����,宜采用固定效應模型。若樣本僅為大母體中的一個隨機子集(如對某城市數(shù)千名居民的抽樣調查)�����,則更適用隨機效應模型����。
?
? ?然而����,更嚴謹?shù)哪P瓦x擇應基于計量經(jīng)濟學假設的檢驗����。隨機效應模型的有效性依賴于“個體效應與解釋變量不相關”的關鍵假設。若該假設成立�����,隨機效應估計量比固定效應估計量更為有效�����;若該假設不成立���,則隨機效應估計量將產(chǎn)生不一致的估計結果����,此時應使用固定效應模型�����。
?
? ?為檢驗這一關鍵假設��,Hausman檢驗是常用的判別方法����。其原假設為個體效應與解釋變量無關(即隨機效應模型假設成立)。檢驗通過比較固定效應與隨機效應估計量的一致性差異構建統(tǒng)計量����。若檢驗拒絕原假設,則表明個體效應與解釋變量存在相關性���,應選擇固定效應模型�����;若無法拒絕原假設�����,則表明隨機效應模型的假設得到支持�,采用隨機效應模型可以獲得更有效的估計結果����。
?
五���、Stata面板數(shù)據(jù)回歸操作流程
?
? ?以下將系統(tǒng)介紹在Stata軟件中進行面板數(shù)據(jù)回歸分析的標準步驟,涵蓋數(shù)據(jù)準備�����、模型設定����、估計檢驗及結果解讀等環(huán)節(jié)。
?
(一)數(shù)據(jù)導入與準備
? ?在導入數(shù)據(jù)前�����,建議對原始數(shù)據(jù)進行預處理����。對于外部數(shù)據(jù)文件,可使用標準導入命令進行加載���;若需從其他軟件或格式轉入�,可通過數(shù)據(jù)編輯器進行轉換����。為確保分析順利進行,變量名稱應使用英文標識���,避免包含中文字符�,同時應妥善處理數(shù)據(jù)中的缺失值�。變量重命名命令可用于建立清晰的分析變量體系。
?
(二)設定面板數(shù)據(jù)結構
? ?進行面板數(shù)據(jù)分析前����,必須明確定義數(shù)據(jù)的面板結構特征。通過指定截面標識變量和時間標識變量���,可將數(shù)據(jù)格式正式聲明為面板數(shù)據(jù)�。該步驟是后續(xù)所有面板數(shù)據(jù)分析命令運行的基礎前提���。
?
(三)模型估計方法
? ?面板數(shù)據(jù)回歸主要提供三種估計方法選擇:
? ??混合最小二乘法:假設所有個體具有相同的截距項����,忽略個體間的異質性特征���。
? ??固定效應模型:通過組內(nèi)變換消除不隨時間變化的個體特征�����,適用于個體效應與解釋變量存在相關性的情況�。
? ??隨機效應模型:假設個體效應與解釋變量不存在相關性,采用廣義最小二乘法進行參數(shù)估計��。
?
(四)模型選擇檢驗
? ?在固定效應模型與隨機效應模型之間進行選擇時���,需要借助統(tǒng)計檢驗����。Hausman檢驗通過比較兩種模型的估計結果是否存在系統(tǒng)性差異�����,為模型選擇提供依據(jù)����。檢驗的原假設支持隨機效應模型。若檢驗結果顯著����,表明個體效應與解釋變量存在相關性,應選擇固定效應模型�����;若不顯著,則支持隨機效應模型�。
? ?當檢驗統(tǒng)計量出現(xiàn)異常值時�,可能表明模型設定存在問題,需重新審視模型的基本假設條件�。
?
(五)結果解讀與報告
? ?模型估計完成后,應系統(tǒng)分析估計結果�����。需重點關注解釋變量的系數(shù)方向���、幅度及其統(tǒng)計顯著性����,同時考察模型的整體擬合效果��。對于固定效應模型����,主要關注組內(nèi)擬合優(yōu)度;隨機效應模型則需要同時考慮組內(nèi)����、組間和總體擬合程度���。最后,應結合具體研究背景�����,對實證結果的經(jīng)濟學或管理學含義進行合理解釋���。
? ?通過遵循上述規(guī)范化操作流程�����,研究者能夠系統(tǒng)完成面板數(shù)據(jù)回歸分析���,確保研究過程的嚴謹性與研究結論的可靠性。
?
樂備實(上海優(yōu)寧維生物科技股份有限公司旗下全資子公司)�,是國內(nèi)專注于提供高質量蛋白檢測以及組學分析服務的實驗服務專家,自2018年成立以來�,樂備實不斷尋求突破,公司的服務技術平臺已擴展到單細胞測序�����、空間多組學、流式檢測�、超敏電化學發(fā)光、Luminex多因子檢測�、抗體芯片、PCR Array�、ELISA、Elispot���、PLA蛋白互作、多色免疫組化�、DSP空間多組學等30多個,建立起了一套涵蓋基因�����、蛋白���、細胞以及組織水平實驗的完整檢測體系�。
?
我們可提供從樣本運輸�、儲存管理、樣本制備�、樣本檢測到檢測數(shù)據(jù)分析的全流程服務。憑借嚴格的實驗室管理流程�����、標準化實驗室操作、原始數(shù)據(jù)儲存體系以及實驗項目管理系統(tǒng)�,已經(jīng)為超過3000家客戶單位提供服務,年檢測樣本超過100萬��,受到了廣大客戶的信任與支持�����。
